
Your RAG is probably broken. Here’s the fix.
Ever feel like you’re talking to an AI that has the attention span of a goldfish?
You give it the exact document with the answer. You point to the right page. You practically highlight the key sentence.
And it still gives you a generic, vague, or just plain wrong answer. 🤖
Frustrating, right?
You’re using Retrieval-Augmented Generation (RAG), the go-to method for getting LLMs to answer questions using specific documents. But you’ve hit a wall.
The dirty secret is that most LLMs, even the giant ones, are terrible at a skill we take for granted: focusing on the right information when there are distractions.
They get confused. They "hallucinate." They ignore the perfect answer right in front of them because it's surrounded by other, less relevant text.
But what if you could teach a model to be an expert test-taker? To not just read the notes, but to know which notes matter for which question, even with a pile of irrelevant stuff trying to distract it?
That’s RAFT. And it’s the reason your Q&A bot is about to get a serious upgrade.
The Exam Analogy: Why Your "Smart" AI is Failing
Imagine you're back in college. You have a final exam.
The professor announces it's an "open-book" exam. Awesome, right? You can bring all your notes!
But there's a catch you don't know about.
You, the diligent student, spent all semester memorizing the textbook, cover to cover. You trained for a "closed-book" exam. You know the facts, figures, and theories by heart.
The day of the exam, you walk in and see everyone else with stacks of textbooks, notes, and articles. The questions aren't simple fact-recall. They require you to find, synthesize, and cite information from a specific chapter in the textbook, ignoring everything else.
You panic.
You know the answer is in your brain somewhere, but you're not practiced at quickly finding it in the book. You waste time flipping through pages, getting distracted by interesting-but-irrelevant charts. The student next to you, who barely studied but is a master at using an index, is acing the test.
This is the exact problem with most LLMs used in RAG systems today.
- Standard LLMs are the "Closed-Book" Students: They have been pre-trained on the entire internet. They have a massive amount of general knowledge memorized.
- RAG is the "Open-Book" Exam: It gives the model a specific set of documents ("notes") and asks it to answer a question based only on that context.
The model fails because it was never trained for this specific skill. It wasn't taught how to ignore its vast internal knowledge and focus solely on the provided text, especially when that text contains distracting information.
RAFT trains the model to ace the open-book exam. It teaches the model to pinpoint the exact answer from a specific source, even when it's buried in a pile of irrelevant documents.

So, What Exactly is RAFT?
RAFT stands for Retrieval-Augmented Fine-Tuning.
It’s a fine-tuning technique developed by researchers at UC Berkeley to make Language Models better at in-domain, open-book Q&A.
Let's break that down:
- Fine-Tuning: A process where you take a pre-trained LLM (like Llama 3) and train it a little more on a new, specialized dataset. This hones its skills for a specific task.
- Retrieval-Augmented: This just means the process is designed for a RAG setup, where the model first retrieves documents and then answers the question.
- In-Domain: This is the key. RAFT is for when you need an AI to be an expert on a specific set of documents—your company's knowledge base, a set of legal contracts, medical research papers, etc.
The core idea is simple but brilliant: To make a model good at answering questions from documents, you should train it to answer questions from documents... while also showing it what not to look at.
This is the fundamental difference between RAFT and other methods.
Want a deeper comparison? Check out our detailed guide on RAG vs. Fine-Tuning: When to Use Each.
- Standard Fine-tuning: Teaches the model new knowledge. (Like memorizing the textbook).
- Standard RAG: Gives a general-purpose model some documents and hopes for the best. (Like giving a closed-book student an open-book test).
- RAFT: Teaches the model the skill of finding and citing answers from provided documents, while ignoring distractions. (Like training a student specifically for the open-book exam format).
Who's Behind This?
RAFT was introduced in the paper "RAFT: Adapting Language Models to In-Domain RAG" by Tianjun Zhang, Shishir G. Patil, and other researchers from UC Berkeley's Gorilla LLM team. Their work tackles one of the most practical and persistent problems in applied AI today.
How RAFT Actually Works: The Secret Sauce
The magic of RAFT lies in its unique training method. It doesn't just show the model a question and the right answer. It creates a realistic test-taking environment.
Here’s the process:
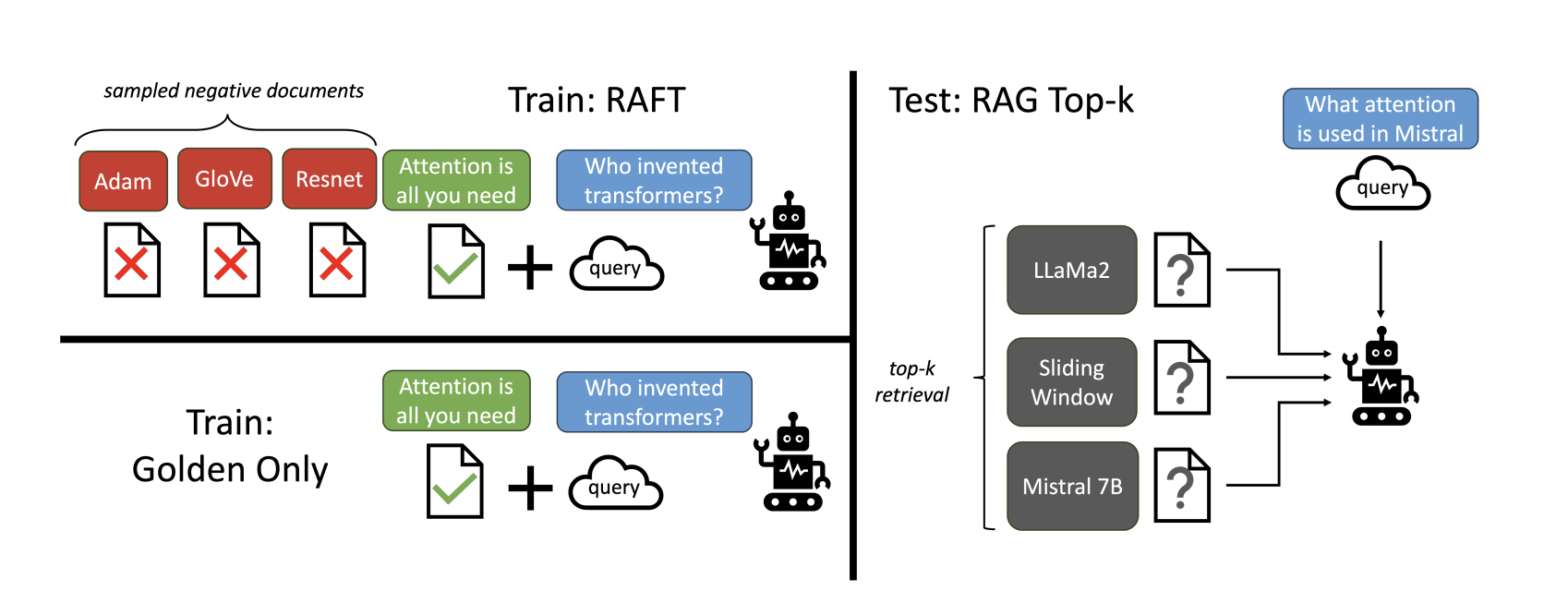
1. Contextual Training with "Distractors"
This is the absolute core of RAFT.
For each question in your dataset, you don't just provide the single document containing the answer. Instead, you create a "context packet" that includes:
- The "Golden" Document: The one perfect document that contains the answer to the question.
- "Distractor" Documents: A handful of other documents from your knowledge base. These are relevant to the overall topic but do not contain the answer to the specific question being asked.
The model is then trained to answer the question while citing its reasoning and evidence only from the golden document.
But why not just train the model with only the golden document?
If you only show the model the perfect answer every time, it doesn't learn how to handle noise. It learns a very simple skill: "copy the answer from the single document I'm given." In the real world, a RAG system will almost always retrieve multiple documents, some of which are irrelevant. Without training on distractors, the model is unprepared for this and will get easily confused. The distractors are essential for teaching the model the robust, real-world skill of discerning what's important, not just repeating it.
Example:
Imagine your knowledge base is about car maintenance.
- Question: "What is the recommended oil change interval for a 2024 Honda Civic?"
- Golden Document: The official 2024 Honda Civic service manual, page 87.
- Distractor Docs:
- An article about the history of synthetic oil.
- The service manual for a Ford F-150.
- A blog post about changing your own windshield wipers.
- A forum discussion about the best tires for snow.
The model must learn to ignore the Ford manual, the oil history, the wipers, and the tires, and correctly answer based only on the Civic manual. By repeatedly training on thousands of such examples, the model gets incredibly good at ignoring noise.
2. Chain-of-Thought Reasoning
RAFT doesn't just want the right answer. It wants the model to show its work.
If you’re curious how multi-step reasoning scales in large models, explore our breakdown on Hierarchical Reasoning Model Explained.
The training data is formatted to encourage a step-by-step reasoning process. This is called Chain-of-Thought (CoT). The model is taught to first think about the problem, identify the key information in the golden document, and then construct the final answer based on that evidence.
An answer in a RAFT-trained model looks something like this:
Answer:
Here's a thinking process to answer the user's query:
- Identify the core question: The user wants to know the oil change interval for a 2024 Honda Civic.
- Scan the provided documents for keywords: Look for "2024 Honda Civic," "oil change," "interval," "maintenance."
- Locate the relevant sentence in the golden document: Document [Civic_Manual.pdf] states, "For the 2024 Civic model, it is recommended to change the engine oil every 7,500 miles or 12 months, whichever comes first."
- Synthesize the final answer: The recommended oil change interval for a 2024 Honda Civic is every 7,500 miles or 12 months.
This forces the model to be more deliberate and less prone to making up facts. It has to justify its answer with evidence from the text.
3. Adaptive Learning
The training process is designed to make the model robust. It's trained on examples with varying numbers of distractor documents. Sometimes there might be only 1 distractor, other times there might be 9. This teaches the model that the position and quantity of the golden document can change, making it more flexible and adaptable at test-time.
How to Build a RAFT-Trained Model
Let's get practical. How do you actually do this?
Step 1: Prepare the RAFT Dataset
This is the most important step. Your dataset needs three things for each entry:
- A question.
- A collection of documents (your "context packet").
- A high-quality, Chain-of-Thought style answer that only uses information from one of the documents in the context.
Here’s what a single training example could look like conceptually:
Question:
What material is the primary mirror of the James Webb Space Telescope (JWST) coated with to optimize it for infrared observation?
Context:
[Distractor Doc]: The Hubble Space Telescope's 2.4-meter primary mirror is made of ultra-low expansion glass and coated with layers of aluminum and magnesium fluoride for visible and ultraviolet light reflectivity.[Golden Doc Snippet 1]: The James Webb Space Telescope is a large infrared telescope with a 6.5-meter primary mirror.[Golden Doc Snippet 2]: Each of the 18 hexagonal segments of the JWST's mirror is made of beryllium and is coated with a microscopically thin layer of gold, which is highly reflective of infrared light.
Instruction to the Model:
Given the question, context and answer above, provide a logical reasoning for that answer. Please use the format of: ##Reason: {reason} ##Answer: {answer}.
Desired CoT Answer (What the model is trained to generate):
##Reason: The question asks what the JWST's mirror is coated with. The document ##begin_quote## The Hubble Space Telescope's 2.4-meter primary mirror... ##end_quote## is a distractor as it discusses a different telescope. The document ##begin_quote## Each of the 18 hexagonal segments of the JWST's mirror is made of beryllium and is coated with a microscopically thin layer of gold... ##end_quote## directly answers the question by specifying the coating material. Therefore, the JWST's primary mirror is coated with gold. ##Answer: Gold
Creating this dataset is the bulk of the work. You need high-quality Q&A pairs for your specific domain.
Step 2: The Training Process
Once you have your dataset, you use it to fine-tune a base LLM. The RAFT paper found that even smaller, capable models can outperform giants after this training.
The training loop feeds the model the question and the context and trains it to generate the cot_answer. Over thousands of iterations, the model learns the skill of ignoring the distractors and reasoning from the golden context.
An interesting finding from the paper: You should always train the LLM with the golden context present. The goal isn't to test the model's memory; it's to train its ability to reason with provided information. Leaving out the golden context would be like trying to teach a student to solve a math problem without giving them the necessary formula. It doesn't work.
When to Use RAFT vs. When to Use Standard RAG
This is the million-dollar question. Is RAFT always better?
Not necessarily. It depends on your use case and budget.
| Scenario | Best Model | Why? | Cost Implications |
|---|---|---|---|
| You need expert-level Q&A on a fixed, specific domain. (e.g., a chatbot for your company's HR policies, a tool for paralegals to query legal documents). | RAFT | Your accuracy needs to be extremely high, and the cost of a wrong answer is significant. You need the model to be robust against "hallucinations" and distractions within your own documents. | Higher upfront cost. You need to invest time and compute resources to create the dataset and fine-tune the model. Lower inference cost. You can use a smaller, fine-tuned model (like a 7B parameter model) that is cheaper to run than a giant one (like GPT-4). |
| You are building a general-purpose Q&A tool across many topics. (e.g., a research assistant that can answer questions from any PDF the user uploads). | RAG without Training | The domain is constantly changing. You can't possibly fine-tune a model on every document a user might upload. You rely on the raw power of a large, general-purpose model. | Lower upfront cost. No training required. You just set up the RAG pipeline with an API call to a large model. Higher inference cost. You are paying for every call to a powerful, expensive model like GPT-4 or Claude 3. This can get very expensive at scale. |
| You need a quick prototype or your accuracy requirements are not strict. | RAG without Training | It's the fastest way to get started. You can have a working RAG system in a few hours. Perfect for MVPs and internal tools where occasional errors are acceptable. | Low upfront, potentially high long-term cost if usage is high. |
The bottom line: If you're a business building a product around a specific knowledge base, the upfront investment in RAFT will likely pay for itself through higher accuracy and lower long-term inference costs.
How Good is RAFT? The Performance Data
The RAFT paper tested their method across several datasets, including medical (PubMed), legal (HotpotQA), and coding (Hugging Face API docs).
The results were striking.
A RAFT-fine-tuned Llama2-7B model consistently outperformed standard RAG using GPT-3.5 and even matched or beat GPT-4 on in-domain question answering.
Let that sink in. A small, open-source 7-billion parameter model, after RAFT training, was more accurate at this specific task than a massive, closed-source model that is orders of magnitude larger and more expensive to run.
Example where RAFT did better:
On the HotPot QA dataset, a model was asked to identify the screenwriter for the film "Evolution," starring Nicolas Cage and Téa Leoni. The provided context included the correct information (David Weissman is a screenwriter for "Evolution") but also a tricky distractor: a document about the film "The Family Man," which also stars Nicolas Cage and Téa Leoni. A less-advanced model got confused by the shared actors and incorrectly answered with the name of the wrong film. RAFT, having been trained to ignore such distractions, correctly identified David Weissman as the answer from the right document.
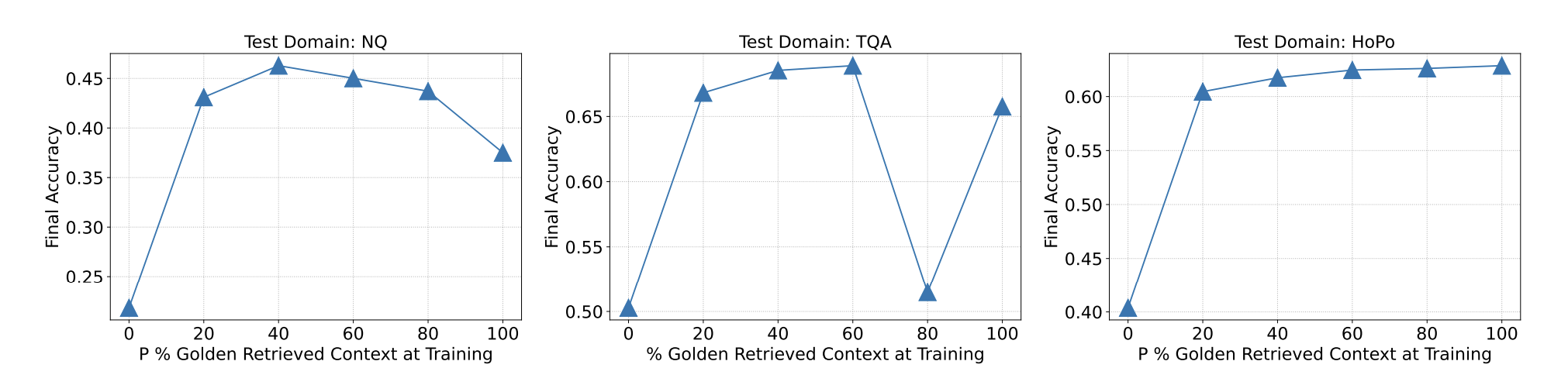
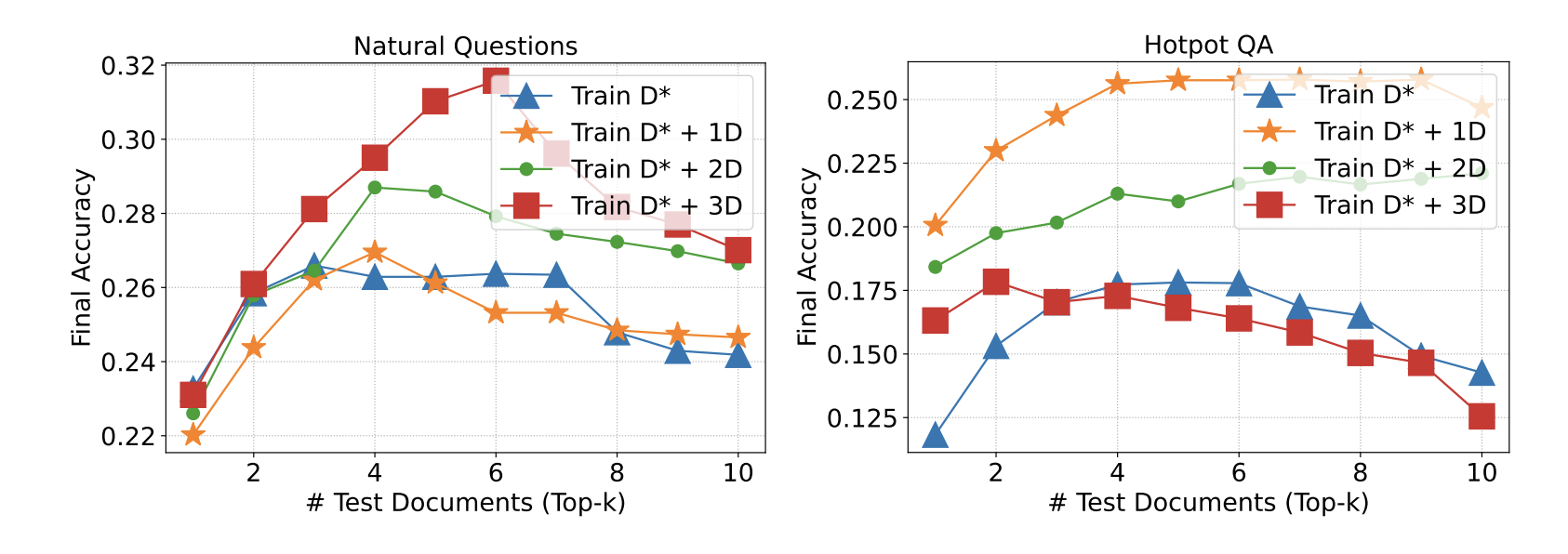
How many documents are best? (The top-k question)
The researchers also tested how many documents to retrieve for the context. They found a sweet spot.
The best performance was achieved when providing 2-4 documents (k=5): 1 golden document and 2-4 distractors.
Performance was still strong with 2 or 10 documents, but 2-4 seemed to be the optimal number for training and testing. This gives the model enough distraction to learn from, without overwhelming its context window.
Which Model Works Best for RAFT?
Not all models are created equal when it comes to RAFT. Because it's a fine-tuning method, you need a model that is receptive to this kind of training.
What Makes a Model a Good Candidate?
- Good Reasoning & CoT Abilities: The model needs a strong baseline ability to "think step-by-step." Models known for strong reasoning make better RAFT students.
- Strong Context Window: While you train on a fixed number of documents, at test-time you might want to use more. A model that can handle a large context is beneficial.
- Open Weights: This is non-negotiable. You need access to the model's weights to be able to fine-tune it. This rules out API-only models like GPT-4 or Claude.
The Recommended Model (as of mid-2025)
The current champion for new RAFT experiments is Llama-3.1-8B-Instruct.
It hits the trifecta:
- It has excellent reasoning capabilities for its size.
- It has a large context window.
- It's open-weight and has a massive support community.
Why Not Just Use a Bigger Model?
This is a common question. Why not just use a 70B or even a 400B model?
- Cost: Fine-tuning and running a 70B model is exponentially more expensive than an 8B model.
- Diminishing Returns: The RAFT paper showed that the skill learned through training was more important than the raw size of the model. The 7B RAFT model beat much larger models that didn't have this specialized skill.
- Speed: Smaller models are faster. For a real-time chatbot application, the speed of an 8B model is a huge advantage.
Using a bigger model is like using a sledgehammer to crack a nut. RAFT is about crafting a specialized, precise tool for the job.
Real-World Industry Applications of RAFT
RAFT isn't just a research concept. It's being deployed to solve real business problems.
- Customer Support: Training a bot on your company's entire history of support tickets, product manuals, and community forums. The bot can provide accurate, cited answers to customer questions, reducing the load on human agents.
- Legal Tech: A tool for lawyers and paralegals to query tens of thousands of legal documents, contracts, and case files. RAFT ensures the model can find the specific clause in the correct document, ignoring similar but irrelevant cases.
- Healthcare: A clinical support assistant for doctors that can answer questions based on the latest medical research, patient histories, and pharmaceutical guidelines, providing evidence-backed information for decision-making.
- Finance: An analyst bot trained on company filings, earnings calls, and market reports. It can answer specific questions like, "What was the Q2 revenue growth for Company X, according to their 10-Q filing?" while ignoring speculative news articles.
Limitations of RAFT
No technique is perfect. RAFT has its own set of challenges.
- Dataset Creation is Hard: The performance of your RAFT model is 100% dependent on the quality of your training dataset. Creating thousands of high-quality, Chain-of-Thought Q&A pairs with appropriate distractors is a significant, labor-intensive effort.
- Domain-Specific Only: A RAFT model trained on legal documents will be terrible at answering questions about medicine. Its expertise is narrow, by design. It's not a general-purpose solution.
- Knowledge Cutoff: Like any fine-tuned model, its knowledge is frozen at the time of training. If your documents are updated daily, you need a strategy for continuous re-training, which can be complex and costly.
Conclusion: Stop Hoping, Start Training
For too long, we've treated LLMs in RAG systems like black boxes. We throw documents at them and just hope they figure it out.
RAFT changes the game by acknowledging the core weakness of LLMs—their distractibility—and tackling it head-on.
It's a shift in mindset: from relying on a model's massive, generic knowledge to teaching it the specific, nuanced skill of being a domain expert. It's the difference between hiring a generalist and training a specialist.
Yes, it requires more upfront work. But for any serious application where accuracy, reliability, and trust are paramount, RAFT provides a clear path forward. It’s how you turn your frustrating, goldfish-brained AI into a focused, evidence-driven expert you can actually rely on.
References:
- Zhang, T., Patil, S. G., et al. (2024). RAFT: Adapting Language Models to In-Domain RAG. https://arxiv.org/pdf/2403.10131
- Gorilla LLM Blog. (2024). RAFT: Teaching LLMs to be Better Students for Open-Book Exams. https://gorilla.cs.berkeley.edu/blogs/9_raft.html