
Ever wonder if your AI is actually smart or just good at guessing?
You've spent weeks, maybe months, building a conversational AI, whether Voice or Text. It feels ready. But how do you know it won't go off the rails with a real user?
Most teams fly blind here. They launch and pray.
But top 1% companies? They do something different. They have a secret weapon to make sure their AI is sharp, reliable, and ready for anything.
Want to know what it is?
So, What is an "Eval"?
Think of an eval (short for evaluation) as a final exam for your AI.
It’s a structured test to see if your AI actually understands and responds like a human, or if it's just spitting out memorized answers. It’s how you measure the quality of your AI's conversations.
And the test questions? Those are your eval sets. An eval set is just a curated list of prompts and ideal responses you use to grade your AI's performance.
The name "eval" comes straight from engineering and data science. For decades, before anyone was talking about LLMs, engineers were evaluating everything from new car designs to the accuracy of weather forecasts. It's a classic term for "let's see if this thing actually works."
Why Bother? Isn't Good Training Enough?
You might think, "I have a massive training dataset. Isn't that enough?"
Not quite. Here’s a simple breakdown:
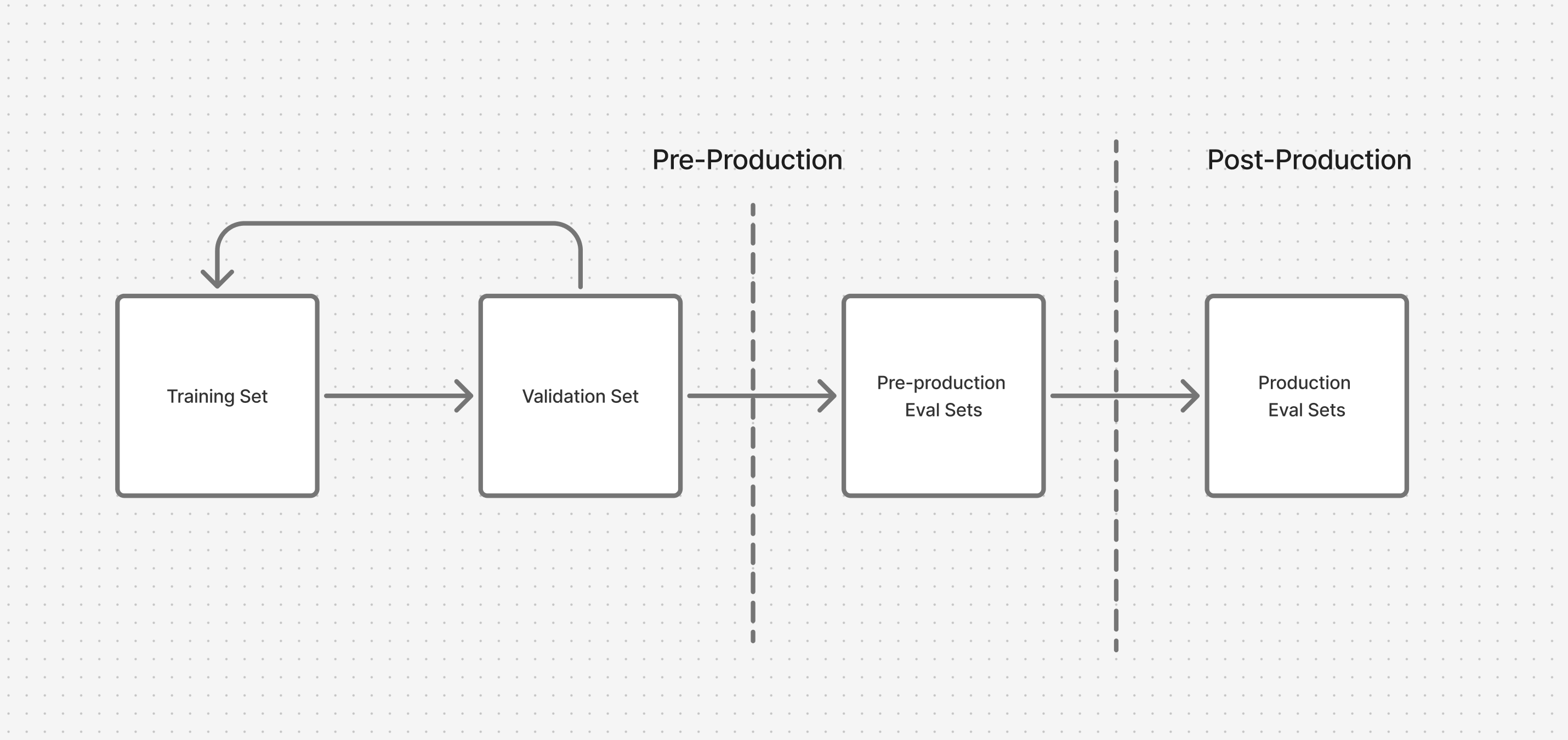
- Training Data: This is the textbook your AI studies to learn. It's massive and teaches the fundamentals.
- Validation Set: These are like pop quizzes during the school year. You use them to tweak your model and make sure it's learning correctly, not just memorising (Overfitting, if you know you know)
- Test Set (Your Eval Set): This is the final, unseen exam. The AI has never encountered these specific questions before. This is the true test of its intelligence and adaptability.
Focusing only on training is like an athlete only practicing drills but never playing in a real game. You need to test your AI in situations it hasn't seen before to know if it can handle the real world. This isn't just about LLMs; this principle applies to almost any machine learning model, from predicting stock prices to identifying cat pictures.
Evals for AI: More Art Than Science
Here’s the thing: evaluating conversational AI is tricky.
There’s often no single "right" answer. Is "Hey, what's up?" better than "Hello, how can I help you?" It depends on the context, the brand's voice, and the user's intent.
This is where the art comes in. You have to define what "good" looks like for your specific use case.
If you're wondering why your AI sometimes sounds confident but gets facts wrong, read our LLMs Hallucination: A Beginner’s Guide to Safer AI. It explains why large language models “hallucinate” — inventing false information — and how proper evals can help detect and reduce these errors before users ever see them.
How to Actually Test Your AI: The Two Main Paths
You have two main options for running evals.
1. Automated Evals
This is when you use software to grade your AI. It's fast, scalable, and great for catching broad issues.
There are two flavours:
- Classic Metrics (BLEU, ROUGE): These are old-school metrics that compare the AI's response to a reference answer based on word overlap.
- Think of it like this: If your reference answer is "The sky is blue," and the AI says "The big sky is blue," it gets a good score. If it says "The ocean is blue," it gets a lower score.
- The catch? They are rigid and miss nuance. "The sky is a beautiful shade of azure" might be a great answer, but it would score poorly because the words don't match.
- Model-Based Evals ("LLM-as-a-Judge"): This is the newer, smarter way. You use another powerful LLM (like GPT-4) to act as a "judge." You give the judge the user's prompt, your AI's answer, and a rubric. The judge then scores the response based on criteria like helpfulness, honesty, and tone.
- Example: You can ask the judge, "On a scale of 1-5, how friendly was this response?"
Curious how these evaluation judges make their decisions? Our Chain of Thought Reasoning — a Mirage blog uncovers how LLMs generate multi-step reasoning paths and why those “thought chains” can sometimes be misleading or inconsistent when judging other models.
When should you use which automated eval?
- Use classic metrics for tasks with a clear right answer, like summarising a document or translating text.
- Use model-based evals for more open-ended, creative, or conversational tasks where quality is subjective.
And yes, you can use them together! A powerful combo is to use a model-based eval for a "Quality Score" (how good does it feel?) and a more traditional check for a "Fact Score" (is the information correct?). This gives you a holistic view and can save a ton of money.
Real-time or after the fact?
- Async/Offline: The most common use case. You run a big batch of tests before deploying a new model version.
- Real-time: This is more advanced. You can "sample" a small percentage of live user conversations (say, 1%) and run evals on them continuously. This helps you spot problems as they happen without breaking the bank.
Speaking of which, you don't need to eval every single interaction. Sampling your data (testing a smart, representative subset) is a cost-effective way to get a strong signal on performance.
Writing Your "LLM-as-a-Judge" Eval Set
This is where you put on your artist's hat.
1. Curate the Prompts:
Don't just test the easy stuff. You need to test the "unhappy path." This is where the Real art lies.
- Include confusing questions.
- Add prompts with typos.
- Try to trick your AI.
- Ask it to handle angry or frustrated users.
- This is how you find the breaking points before your users do.
2. Design the Rubric:
This is your scorecard. Be crystal clear.
- Bad Rubric: "Was the response good?"
- Good Rubric:
- Is the answer factually correct? (Yes/No)
- Does it directly answer the user's question? (Yes/No)
- What is the tone? (Friendly, Formal, Robotic)
- Does it contain any harmful or biased language? (Yes/No)
The Gold Standard: Human in the Loop
Automated systems are great, but nothing beats a human's judgment. This is your final, most important quality check.
There are two common ways to do this:
1. Rating on a Scale:
- How it works: You show the reviewer the AI's response and ask them to rate it on a scale (e.g., 1-5) based on your rubric.
- Pros: Simple, fast, generates easy-to-analyze quantitative data.
- Cons: Ratings can be subjective. My "4" might be your "5."
2. Side-by-Side Comparison:
- How it works: You show the reviewer two different responses to the same prompt (e.g., from your old model and your new model) and ask, "Which one is better and why?"
- Pros: Forces a clear decision, reduces subjectivity, and gives you rich qualitative feedback on why one is better.
- Cons: Slower, more complex to set up.
Where Evals Fit in Your Workflow
Don't think of evals as a one-time thing.
- Pre-Production: Initially, your eval set IS your test set. It's the final gate before you ship. If the model can't pass this test, it doesn't go live.
- Production: Once your AI is live, evaluation becomes a continuous health check. You regularly test samples of real user data to monitor for performance drift and ensure your AI stays sharp.
Ready to stop guessing and start knowing?
Building a robust eval strategy is the single biggest step you can take to move from a "maybe-it-works" AI to one that consistently delivers.
Start small. Create a 20-prompt eval set today that tests the most critical (and trickiest) parts of your conversations. You'll be amazed at what you find.